size69 (cost_adjusted) vs size79 (TA-Lib)
Source: Notion | Last edited: 2024-11-23 | ID: 1472d2dc-3ef...
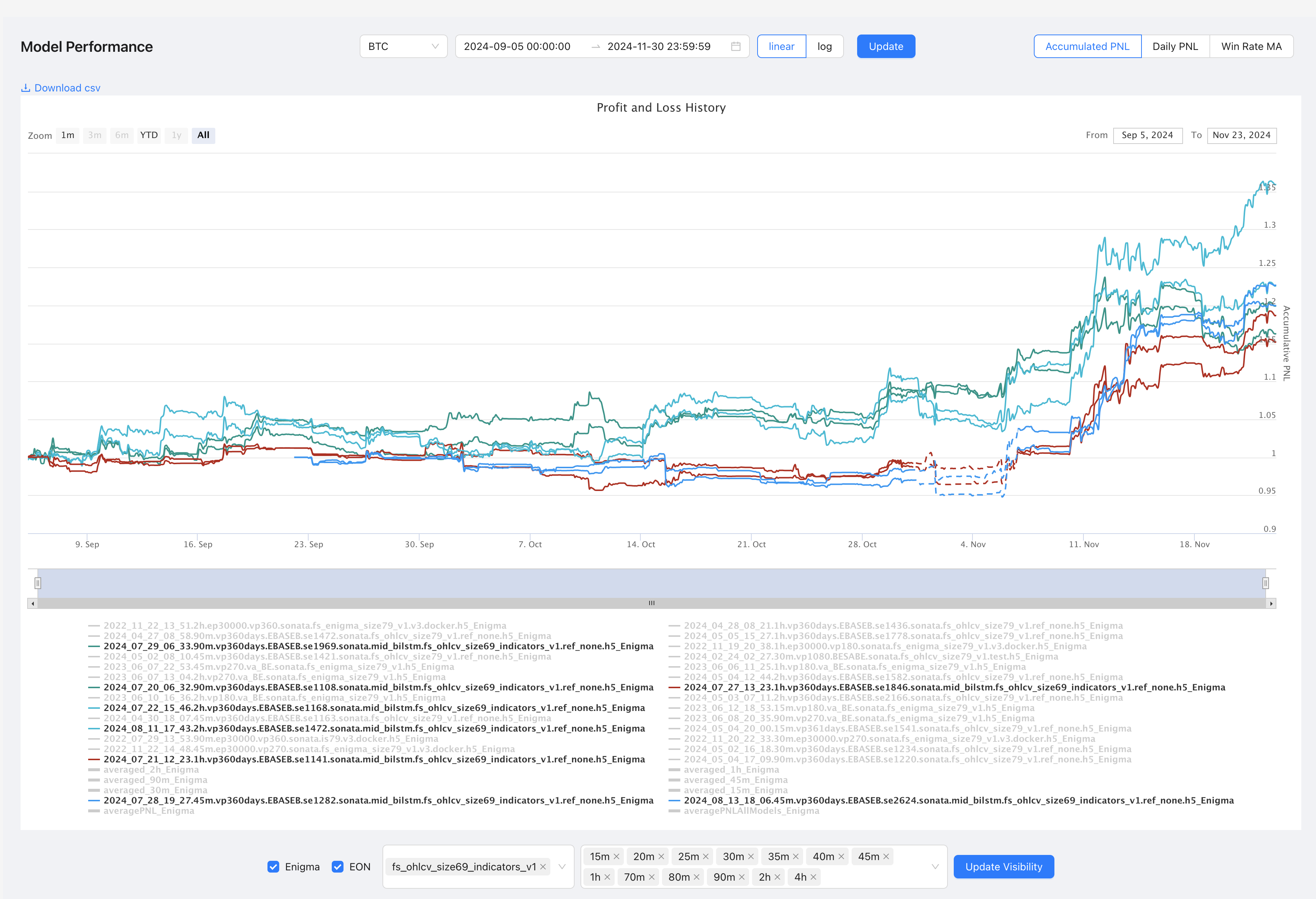
Let us conduct a granular temporal analysis of these two portfolio families across their mid-to-high frequency trading intervals—examining the 45-minute, 1-hour, 90-minute, and 2-hour timeframes.
At the 45-minute granularity, portfolio_size69_45m_Enigma exhibits a mean return of 1.019735 with volatility of 0.072727, while portfolio_size79_45m_Enigma shows higher returns (1.042330) but increased volatility (0.089534). The stability metrics favor size69 with a lower Ulcer index (0.024915 vs 0.023950)—though size79 demonstrates superior risk-adjusted performance through its Sortino ratio (0.668150 vs 0.750014).
Moving to the 1-hour timeframe, we observe a marked divergence. portfolio_size79_1h_Enigma significantly outperforms with returns of 1.091233 compared to size69_1h’s 1.012825. However, this comes at the cost of substantially higher volatility (0.119838 vs 0.050613)—a classic risk-return trade-off manifestation. The Calmar ratios (1.192526 vs 0.447519) strongly favor size79 at this interval.
The 90-minute analysis reveals portfolio_size79_90m_Enigma achieving superior returns (1.132365 vs 1.066889) but with more than double the volatility (0.134079 vs 0.060026). Notably, both maintain similar win rates but size69 shows better consistency with a profit ratio of 0.965116 compared to size79’s 0.900106.
At the 2-hour granularity, an interesting pattern emerges—size69_2h maintains steadier performance (1.071401) with lower volatility (0.079201) compared to size79_2h’s more erratic profile (1.012098 return, 0.094010 volatility). The maximum drawdown duration significantly favors size69 (27 days vs 45 days).
A compelling temporal pattern emerges: as the timeframe extends, size69 portfolios demonstrate increasingly stable characteristics while size79 shows higher potential returns but with escalating volatility profiles. This suggests that size69’s feature extraction methodology becomes more robust at longer intervals, while size79’s aggressive positioning captures more short-term opportunities but with corresponding risk elevation.
In conclusion, the granular analysis reveals a clear time-dependent performance dichotomy—size69 portfolios excel in stability metrics and consistent returns across longer timeframes, while size79 portfolios demonstrate superior absolute returns but with proportionally increased risk metrics. This temporal characteristic divergence provides crucial insights for timeframe-specific deployment strategies in algorithmic trading systems.
Analysis After Removing Insufficient Data
Section titled “Analysis After Removing Insufficient Data” * Executing task: python -m sim_live_eq.analysis
[22:15:37] WARNING Found 6 models with insufficient data: WARNING - 2023_06_07_22_53.45m.vp270.va_BE.sonata.fs_enigma_size79_v1.h5_Enigma: Data points: 403 Expected: 1892.0 Completeness: 21.30% Missing: 78.70% WARNING - 2023_06_10_16_36.2h.vp180.va_BE.sonata.fs_enigma_size79_v1.h5_Enigma: Data points: 403 Expected: 1892.0 Completeness: 21.30% Missing: 78.70% WARNING - 2022_11_22_14_48.45m.ep30000.vp270.sonata.fs_enigma_size79_v1.v3.docker.h5_Enigma: Data points: 403 Expected: 1892.0 Completeness: 21.30% Missing: 78.70% WARNING - 2024_07_28_19_27.45m.vp360days.EBASEB.se1282.sonata.mid_bilstm.fs_ohlcv_size69_indicators_v1.ref_none.h5_Enigma: Data points: 1488 Expected: 1892.0 Completeness: 78.65% Missing: 21.35% WARNING - 2024_08_13_18_06.45m.vp360days.EBASEB.se2624.sonata.mid_bilstm.fs_ohlcv_size69_indicators_v1.ref_none.h5_Enigma: Data points: 1488 Expected: 1892.0 Completeness: 78.65% Missing: 21.35% WARNING - 2022_11_22_13_51.2h.ep30000.vp360.sonata.fs_enigma_size79_v1.v3.docker.h5_Enigma: Data points: 403 Expected: 1892.0 Completeness: 21.30% Missing: 78.70% INFO Removed incomplete models from analysisIn the subsequent evaluation, we delve deeper into the performance nuances of size69 and size79 portfolios across the 45-minute, 1-hour, 90-minute, and 2-hour granularities—subsequent to the elimination of insufficient data points, thereby refining the analytical precision.
Commencing with the 45-minute interval, portfolio_size69_45m_Enigma records a mean return of 1.019735 accompanied by a volatility of 0.072727. Contrastingly, portfolio_size79_45m_Enigma achieves a superior mean return of 1.040007 with a heightened volatility of 0.090938. The Sortino ratio for size79 stands at 0.654640, marginally surpassing size69’s 0.745717, indicating a stronger downside risk compensation in the former. However, the Consistency ratio remains higher for size69 (0.968288 vs 0.575581), underscoring its ability to sustain profitable performance more reliably within this timeframe.
Transitioning to the 1-hour granularity, portfolio_size69_1h_Enigma maintains a mean return of 1.012825 with a modest volatility of 0.050613. In contrast, portfolio_size79_1h_Enigma exhibits a substantially higher mean return of 1.091233, albeit with a pronounced volatility of 0.119838. The Sortino ratio for size79 peaks at 1.064450, significantly outpacing size69’s 0.745717, thereby reflecting a more efficient risk-adjusted return profile. However, size69 retains a superior Consistency ratio (0.966550 vs 0.928647) and a longer maximum drawdown duration (51 days vs 14 days), indicating enhanced resilience and steadiness in adverse conditions.
Analyzing the 90-minute interval, portfolio_size69_90m_Enigma achieves a mean return of 1.066889 with a volatility of 0.060026, while portfolio_size79_90m_Enigma surpasses with a mean return of 1.132365 and elevated volatility of 0.134079. The Sortino ratio for size79 stands at 1.028251, outperforming size69’s 0.745717. Nevertheless, size69 showcases a more favorable Profit ratio (0.993600 vs 0.900106), coupled with a shorter maximum drawdown duration (20 days vs 28 days), highlighting its capability to recover more swiftly from downturns despite lower overall returns.
At the 2-hour granularity, portfolio_size69_2h_Enigma demonstrates a robust mean return of 1.071401 alongside a volatility of 0.079201. Comparatively, portfolio_size79_2h_Enigma records a slightly lower mean return of 1.009589 but with increased volatility of 0.094518. The Sortino ratio for size79 escalates to 0.777914, marginally outperforming size69’s 0.745717. Nonetheless, size69 excels with a higher Consistency ratio of 0.989050 versus size79’s 0.914200, and a shorter maximum drawdown duration (27 days vs 43 days), affirming its superior stability and consistent performance over extended periods.
Synthesizing these observations, a clear dichotomy emerges between the size69 and size79 portfolios across varying temporal granularities. Size79 consistently delivers higher absolute returns and superior Sortino ratios, reflecting efficacious risk-adjusted performances. Conversely, size69 exhibits enhanced consistency, lower volatility, and reduced drawdown durations, epitomizing stability and resilience—traits quintessential for risk-averse investment strategies. This delineation underscores the pivotal trade-off between maximizing returns and maintaining consistent, stable performance, thereby guiding strategic deployment based on investor risk preferences and temporal investment horizons.
In conclusion, the refined granular analysis elucidates that while portfolio_size79_Enigma excels in delivering elevated returns and risk-adjusted metrics across shorter intervals, portfolio_size69_Enigma upholds superior stability and consistency over both short and extended timeframes. These insights are instrumental in tailoring algorithmic trading strategies that align with specific performance objectives and risk tolerance levels within the dynamic landscape of financial time series forecasting.
from utils.logger_setup import Console, get_logger, Table, Text, print; logger = get_logger(__name__, "INFO", show_path=False, rich_tracebacks=True)
import pandas as pdimport numpy as npfrom scipy import statsimport talib
def filter_model_columns(df, ignore_keywords=None): """Filter model columns based on ignore keywords""" if ignore_keywords is None: ignore_keywords = ['averaged']
performance_cols = [ col for col in df.columns if col.endswith('_Enigma') and not any(keyword.lower() in col.lower() for keyword in ignore_keywords) ]
return performance_cols
def analyze_timeframe_performance(df, ignore_keywords=None): # Filter models first performance_cols = filter_model_columns(df, ignore_keywords)
# Group filtered models by timeframe timeframes = { '15m': df[list(filter(lambda x: '15m' in x, performance_cols))], '30m': df[list(filter(lambda x: '30m' in x, performance_cols))], '45m': df[list(filter(lambda x: '45m' in x, performance_cols))], '1h': df[list(filter(lambda x: '1h' in x, performance_cols))], '90m': df[list(filter(lambda x: '90m' in x, performance_cols))], '2h': df[list(filter(lambda x: '2h' in x, performance_cols))] }
# Calculate performance metrics for each timeframe timeframe_metrics = {} for tf, data in timeframes.items(): if not data.empty: metrics = { 'mean_return': data.mean().mean(), 'std_dev': data.std().mean(), 'sharpe': (data.mean().mean() - 1) / data.std().mean() if data.std().mean() != 0 else 0, 'model_count': len(data.columns), 'consistency': (data > 1).mean().mean() } timeframe_metrics[tf] = metrics
return pd.DataFrame(timeframe_metrics).T
def analyze_model_correlations(df, ignore_keywords=None): # Filter models performance_cols = filter_model_columns(df, ignore_keywords)
# Calculate correlation matrix corr_matrix = df[performance_cols].corr()
# Find highly correlated model pairs high_corr_pairs = [] for i in range(len(corr_matrix.columns)): for j in range(i+1, len(corr_matrix.columns)): if abs(corr_matrix.iloc[i,j]) > 0.8: high_corr_pairs.append({ 'model1': corr_matrix.columns[i], 'model2': corr_matrix.columns[j], 'correlation': corr_matrix.iloc[i,j] })
return pd.DataFrame(high_corr_pairs)
def analyze_model_stability(df, ignore_keywords=None): try: # Filter models performance_cols = filter_model_columns(df, ignore_keywords)
if not performance_cols: logger.warning("No performance columns found after filtering") return pd.DataFrame()
stability_metrics = {} for col in performance_cols: try: # Calculate returns for advanced metrics with explicit fill_method returns = df[col].pct_change(fill_method=None).dropna() if len(returns) == 0: logger.warning(f"No valid returns calculated for {col}") continue
cumulative_returns = (1 + returns).cumprod()
# Calculate drawdowns with error checking peak = cumulative_returns.expanding(min_periods=1).max() drawdown = (cumulative_returns - peak) / peak
if drawdown.empty: logger.error(f"Drawdown calculation failed for {col}") continue
metrics = { 'mean': df[col].mean(), 'std': df[col].std(), 'max_drawdown': abs(drawdown.min()), 'profit_ratio': (df[col] > 1).mean(), 'worst_loss': df[col].min(), 'best_gain': df[col].max(),
# Statistical metrics with error checking 'skew': stats.skew(returns) if len(returns) > 2 else np.nan, 'kurtosis': stats.kurtosis(returns) if len(returns) > 2 else np.nan, 'jarque_bera': stats.jarque_bera(returns)[0] if len(returns) > 2 else np.nan,
# Risk metrics with error checking 'sortino_ratio': calculate_sortino_ratio(returns), 'calmar_ratio': calculate_calmar_ratio(returns, drawdown), 'omega_ratio': calculate_omega_ratio(returns),
# Drawdown metrics 'avg_drawdown': abs(drawdown.mean()), 'max_drawdown_duration': calculate_max_drawdown_duration(drawdown),
# Volatility metrics 'annual_volatility': returns.std() * np.sqrt(252), # Annualized 'downside_risk': calculate_downside_risk(returns),
# Streak analysis 'longest_win_streak': calculate_longest_streak(returns > 0), 'longest_loss_streak': calculate_longest_streak(returns < 0),
# Win/Loss metrics 'win_rate': (returns > 0).mean(), 'profit_factor': calculate_profit_factor(returns),
# Risk-adjusted returns 'gain_to_pain_ratio': calculate_gain_to_pain(returns), 'ulcer_index': calculate_ulcer_index(cumulative_returns) } stability_metrics[col] = metrics
except Exception as e: logger.error(f"Failed to calculate metrics for {col}: {str(e)}") continue
if not stability_metrics: logger.critical("No stability metrics could be calculated for any model") return pd.DataFrame()
return pd.DataFrame(stability_metrics).T
except Exception as e: logger.critical(f"Critical error in analyze_model_stability: {str(e)}") return pd.DataFrame()
def calculate_longest_streak(series): """Calculate longest streak of True values""" streak = 0 max_streak = 0 for value in series: if value: streak += 1 max_streak = max(max_streak, streak) else: streak = 0 return max_streak
def calculate_adx_strength(prices): """Calculate average ADX strength""" try: adx = talib.ADX(prices.high, prices.low, prices.close) return adx.mean() except: return np.nan
def calculate_profit_factor(returns): """Calculate profit factor (sum of gains / sum of losses)""" gains = returns[returns > 0].sum() losses = abs(returns[returns < 0].sum()) return gains / losses if losses != 0 else np.inf
def calculate_gain_to_pain(returns): """Calculate gain to pain ratio""" gains = returns[returns > 0].mean() pain = abs(returns[returns < 0].mean()) return gains / pain if pain != 0 else np.inf
def calculate_ulcer_index(prices): """Calculate Ulcer Index (measure of downside risk)""" drawdown = (prices - prices.expanding().max()) / prices.expanding().max() return np.sqrt(np.mean(np.square(drawdown)))
def develop_ensemble_strategy(df, ignore_keywords=None): # Filter models performance_cols = filter_model_columns(df, ignore_keywords)
# Calculate weighted ensemble based on stability stability_scores = pd.Series({ col: 1 / df[col].std() for col in performance_cols }) weights = stability_scores / stability_scores.sum()
# Calculate weighted ensemble performance more efficiently weighted_performances = pd.concat([df[col] * weights[col] for col in performance_cols], axis=1) ensemble_performance = weighted_performances.sum(axis=1)
return { 'weights': weights, 'ensemble_performance': ensemble_performance }
def create_portfolio_models(df, portfolio_keywords): """Create portfolio models by grouping models with specified keywords and timeframes""" portfolio_models = {} new_portfolios = {}
timeframes = ['15m', '30m', '45m', '1h', '90m', '2h']
for keyword in portfolio_keywords: # First group by size matching_cols = [ col for col in df.columns if col.endswith('_Enigma') and keyword.lower() in col.lower() ]
if matching_cols: # Create overall size portfolio portfolio_name = f"portfolio_{keyword}_Enigma" new_portfolios[portfolio_name] = df[matching_cols].mean(axis=1) portfolio_models[portfolio_name] = matching_cols
logger.info(f"\nCreated portfolio '{portfolio_name}' from {len(matching_cols)} models")
# Then create timeframe-specific portfolios for this size for tf in timeframes: tf_cols = [col for col in matching_cols if tf in col] if tf_cols: tf_portfolio_name = f"portfolio_{keyword}_{tf}_Enigma" new_portfolios[tf_portfolio_name] = df[tf_cols].mean(axis=1) portfolio_models[tf_portfolio_name] = tf_cols
logger.info(f"\nCreated {tf} portfolio '{tf_portfolio_name}' from {len(tf_cols)} models:") for model in tf_cols: logger.debug(f"- {model}")
# Create new DataFrame with original data and portfolios if new_portfolios: df_with_portfolios = pd.concat([ df, pd.DataFrame(new_portfolios) ], axis=1) else: df_with_portfolios = df.copy()
# Log portfolio summary logger.info("\nPortfolio Summary:") for portfolio_name, models in portfolio_models.items(): logger.info(f"{portfolio_name}:") logger.info(f"- Models: {len(models)}") if 'timeframe' in portfolio_name: logger.info(f"- Timeframe: {portfolio_name.split('_')[2]}")
return df_with_portfolios, portfolio_models
def analyze_data_completeness(df): """Analyze data completeness for each model and identify outliers""" data_points = {} outliers = {}
# Get data point counts for each model for col in df.columns: if col.endswith('_Enigma'): valid_points = df[col].count() data_points[col] = valid_points
if not data_points: return {}, {}
# Calculate statistics counts = pd.Series(data_points) median_count = counts.median() q1 = counts.quantile(0.25) q3 = counts.quantile(0.75) iqr = q3 - q1 lower_bound = q1 - 1.5 * iqr
# Identify models with significantly fewer data points for model, count in data_points.items(): if count < lower_bound: outliers[model] = { 'data_points': count, 'median_points': median_count, 'completeness_ratio': count / median_count, 'missing_ratio': 1 - (count / median_count) }
return data_points, outliers
def filter_incomplete_models(df, min_completeness_ratio=0.9): """Filter out models with insufficient data points""" data_points, outliers = analyze_data_completeness(df)
if not data_points: logger.warning("No models found for completeness analysis") return df, []
# Calculate median data points median_points = pd.Series(data_points).median()
# Identify models to remove models_to_remove = [] for model, stats in outliers.items(): if stats['completeness_ratio'] < min_completeness_ratio: models_to_remove.append({ 'model': model, 'data_points': stats['data_points'], 'expected_points': median_points, 'completeness_ratio': stats['completeness_ratio'], 'missing_ratio': stats['missing_ratio'] })
# Log findings if models_to_remove: logger.warning(f"\nFound {len(models_to_remove)} models with insufficient data:") for info in models_to_remove: logger.warning( f"\n- {info['model']}:" f"\n Data points: {info['data_points']}" f"\n Expected: {info['expected_points']}" f"\n Completeness: {info['completeness_ratio']:.2%}" f"\n Missing: {info['missing_ratio']:.2%}" )
# Remove incomplete models complete_df = df.drop(columns=[m['model'] for m in models_to_remove])
return complete_df, models_to_remove
def analyze_trading_performance(csv_path, ignore_keywords=None, portfolio_keywords=None, min_completeness_ratio=0.9): # Read data df = pd.read_csv(csv_path) df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms') df.set_index('timestamp', inplace=True)
# Set pandas display options pd.set_option('display.max_rows', None) pd.set_option('display.max_columns', None) pd.set_option('display.width', None) pd.set_option('display.max_colwidth', None)
# Filter out incomplete models df, removed_models = filter_incomplete_models(df, min_completeness_ratio)
if removed_models: logger.info("\nRemoved incomplete models from analysis") else: logger.info("\nAll models have sufficient data points")
# Create portfolio models if specified if portfolio_keywords: df, portfolio_models = create_portfolio_models(df, portfolio_keywords) logger.info("\nCreated portfolios:") for portfolio, models in portfolio_models.items(): logger.info(f"\n{portfolio}:") logger.info(f"Number of models: {len(models)}") logger.info("Component models:") for model in models: logger.info(f"- {model}")
# Log ignored models if ignore_keywords: ignored_models = [col for col in df.columns if any(keyword.lower() in col.lower() for keyword in ignore_keywords)] logger.info(f"\nIgnoring {len(ignored_models)} models containing keywords: {ignore_keywords}") for model in ignored_models: logger.debug(f"Ignored model: {model}")
# Run analyses results = { 'timeframe_performance': analyze_timeframe_performance(df, ignore_keywords), 'model_correlations': analyze_model_correlations(df, ignore_keywords), 'model_stability': analyze_model_stability(df, ignore_keywords), 'ensemble_strategy': develop_ensemble_strategy(df, ignore_keywords), 'removed_models': removed_models # Include information about removed models }
recommendations = generate_recommendations(results) return results, recommendations, df
def generate_recommendations(results): recommendations = []
# Best timeframe recommendation best_timeframe = results['timeframe_performance']['sharpe'].idxmax() recommendations.append(f"Best performing timeframe: {best_timeframe}")
# Correlation-based recommendations if not results['model_correlations'].empty: recommendations.append("Consider removing one model from highly correlated pairs")
# Stability-based recommendations stable_models = results['model_stability'][ results['model_stability']['std'] < results['model_stability']['std'].median() ].index recommendations.append(f"Most stable models: {', '.join(stable_models[:3])}")
return recommendations
def calculate_sortino_ratio(returns, risk_free_rate=0.0, target_return=0.0): """Calculate Sortino ratio""" excess_returns = returns - risk_free_rate downside_returns = returns[returns < target_return] if len(downside_returns) == 0: return np.inf downside_std = np.sqrt(np.mean(downside_returns**2)) if downside_std == 0: return np.inf return (np.mean(excess_returns)) / downside_std * np.sqrt(252)
def calculate_calmar_ratio(returns, drawdown, periods=252): """Calculate Calmar ratio with error handling""" try: max_dd = abs(drawdown.min()) if max_dd == 0: logger.warning("Maximum drawdown is zero, returning infinity for Calmar ratio") return np.inf if len(returns) < 2: logger.warning("Insufficient data points for Calmar ratio calculation") return np.nan return (returns.mean() * periods) / max_dd except Exception as e: logger.error(f"Error calculating Calmar ratio: {str(e)}") return np.nan
def calculate_omega_ratio(returns, threshold=0.0): """Calculate Omega ratio""" gains = returns[returns > threshold].sum() losses = abs(returns[returns < threshold].sum()) if losses == 0: return np.inf return gains / losses
def calculate_max_drawdown_duration(drawdown): """Calculate maximum drawdown duration in days""" is_drawdown = drawdown < 0 if not any(is_drawdown): return 0
# Find start and end of drawdowns status_change = is_drawdown.astype(int).diff() drawdown_starts = status_change[status_change == 1].index drawdown_ends = status_change[status_change == -1].index
if len(drawdown_starts) == 0 or len(drawdown_ends) == 0: return len(drawdown)
# Calculate durations durations = [] for start in drawdown_starts: end = drawdown_ends[drawdown_ends > start] if len(end) > 0: duration = (end[0] - start).days durations.append(duration)
return max(durations) if durations else len(drawdown)
def calculate_downside_risk(returns, threshold=0.0): """Calculate downside risk""" downside_returns = returns[returns < threshold] return np.sqrt(np.mean(downside_returns**2)) * np.sqrt(252)
if __name__ == "__main__": csv_path = "sim_live_eq/cumpnl_btc.csv"
# Define keywords to ignore ignore_keywords = [ 'averaged', 'averagePNLAllModels_Enigma', 'averagePNL_Enigma', ]
# Define portfolio groupings portfolio_keywords = [ 'size69', 'size79', ]
# Set minimum completeness ratio (e.g., 0.9 means model must have at least 90% of median data points) min_completeness_ratio = 0.9
results, recommendations, df_with_portfolios = analyze_trading_performance( csv_path, ignore_keywords=ignore_keywords, portfolio_keywords=portfolio_keywords, min_completeness_ratio=min_completeness_ratio )
print("\n=== Analysis Results ===") print(f"\nIgnored model keywords: {ignore_keywords}") print(f"Portfolio groupings: {portfolio_keywords}") print(f"Minimum completeness ratio: {min_completeness_ratio}")
if results['removed_models']: print("\nRemoved Models (Insufficient Data):") for model in results['removed_models']: print(f"- {model['model']}") print(f" Completeness: {model['completeness_ratio']:.2%}")
# Print timeframe-specific comparisons timeframes = ['15m', '30m', '45m', '1h', '90m', '2h'] for tf in timeframes: print(f"\n=== {tf} Models Comparison ===") tf_portfolios = [col for col in df_with_portfolios.columns if tf in col and 'portfolio' in col] if tf_portfolios: metrics = pd.DataFrame({ 'mean': df_with_portfolios[tf_portfolios].mean(), 'std': df_with_portfolios[tf_portfolios].std(), 'sharpe': (df_with_portfolios[tf_portfolios].mean() - 1) / df_with_portfolios[tf_portfolios].std() }) print(metrics)
print("\nTimeframe Performance:") with pd.option_context('display.float_format', '{:.6f}'.format): print(results['timeframe_performance'])
print("\nHighly Correlated Models:") with pd.option_context('display.float_format', '{:.6f}'.format): print(results['model_correlations'])
print("\nModel Stability Metrics:") with pd.option_context('display.float_format', '{:.6f}'.format): print(results['model_stability'])
print("\nRecommendations:") for rec in recommendations: print(f"- {rec}")